微博自动发贴,简单却不容易被注意到的反爬方式
移动端登录后移步 http://m.weibo.cn/mblog 页面发贴,正常思路是:填写消息->其它选项->点击发送。
tv_msg.send_keys("msg")
btn_send.click()
仔细看下细节,会发现,发送按钮一开始是disable的,输入消息后才会变成enable。
所以按理说,代码确实没有问题。可是执行结果是最终停留在这个页面,而且send按钮并没有变成可用的橙色。
测试最后发现,msg输入后,send并不会立即改变状态,而是有一个很小的延迟时间。而因为机器的执行速度极快,导致在send状态改变前,已经执行了click动作。所以发送动作没有如期进行。
在其中加入一点delay解决问题。
tv_msg.send_keys("msg")
time.sleep(0.1)
btn_send.click()
利用 Python + Selenium 实现对页面的指定元素截图(可截长图元素)
对WebElement截图
WebDriver.Chrome自带的方法只能对当前窗口截屏,且不能指定特定元素。若是需要截取特定元素或是窗口超过了一屏,就只能另辟蹊径了。
WebDriver.PhantomJS自带的方法支持对整个网页截屏。
下面提供几种思路。
方式一
针对WebDriver.Chrome
通过WebDriver的js脚本注入功能,曲线救国。
1. 注入第三方html转canvas的js库(见下方推荐)
2. 获取元素html源码
3. 将html转换为canvas
4. 下载canvas
优点: 截取长图容易实现
缺点: 加载第三方库耗费时间,转换原理请参考这篇文章:
将 DOM 对象绘制到 canvas 中
方式二
针对WebDriver.Chrome
截取全图,自行裁剪、拼接
1. 获取元素位置、大小
2. 获取窗口大小
3. 截取包含元素的窗口
4. 进行相应的裁剪和拼接。
具体算法思路很清晰,但需要注意的细节较多。这里就不在赘述。示例代码请移步:
[Github]PythonSpiderLibs
优点: 不需太多js工作,python+少量js代码即可完成
缺点: 拼接等工作会被WebDriver的实现差异、图片加载速度等因素影响,需多加注意。 在保证截图质量的情况下,速度较慢
方式三
针对WebDriver.PhantomJS
由于接口实现的差异,PhantomJS相比于Chrome,可以截取到整个网页。所以获取指定元素的截图也就简单很多
- 截取网页全图
- 裁剪指定元素
driver = webdriver.Chrome()
driver.get('http://stackoverflow.com/')
driver.save_screenshot('screenshot.png')
left = element.location['x']
top = element.location['y']
right = element.location['x'] + element.size['width']
bottom = element.location['y'] + element.size['height']
im = Image.open('screenshot.png')
im = im.crop((left, top, right, bottom))
im.save('screenshot.png')
优点: 实现简单
缺点: 对于高度太高的页面会导致文件过大,处理会有问题,我测试的最大图片尺寸是12.8M。
解决图片加载不完整的问题
参考: 利用 Python + Selenium 自动化快速截图
我们先在首页上执行一段 JavaScript 脚本,将页面的滚动条拖到最下方,然后再拖回顶部,最后才截图。这样可以解决像上面那种按需加载图片的情况。
from selenium import webdriver
import time
def take_screenshot(url, save_fn="capture.png"):
browser = webdriver.Firefox() # Get local session of firefox
browser.set_window_size(1200, 900)
browser.get(url) # Load page
browser.execute_script("""
(function () {
var y = 0;
var step = 100;
window.scroll(0, 0);
function f() {
if (y < document.body.scrollHeight) {
y += step;
window.scroll(0, y);
setTimeout(f, 100);
} else {
window.scroll(0, 0);
document.title += "scroll-done";
}
}
setTimeout(f, 1000);
})();
""")
for i in xrange(30):
if "scroll-done" in browser.title:
break
time.sleep(10)
browser.save_screenshot(save_fn)
browser.close()
if __name__ == "__main__":
take_screenshot("http://codingpy.com")
不同wewbdriver对某些方法的实现不同
Chrome和PhantomJS 的接口差异
抓知乎时的坑,
1. Chrome用WebElement.text可以正常得到值,用PhantomJS只能用 WebElement.get_attribute('innerHTML')
2. WebDriver.Chrome截图只能截当前屏幕区域。WebDriver.PhantomJS截图可以获取整个页面的长图。
其它还有一些坑等待发现
推荐
谈谈爬虫-模拟登录思路
最近在做的sideproject,需要网络上的文章数据。于是顺便学习了下爬虫技术,也算是有些心得体会。写下来分享给刚入坑的新人。
怎么理解模拟登录?
怎么理解模拟登录?
把这句话补全就是: 怎么(让机器)模拟(人在浏览器上的行为)登录(指定的网站)。
那么这个问题实际上问的是: 人通过浏览器登录网站时,浏览器为我们做了哪些事情。
那么我们需要做的只有:写一个脚本,让这个脚本模拟浏览器的行为,做我们希望它做的事情。
有兴趣参考:
当在浏览器地址栏输入一个URL后回车,将会发生的事情?
那么,
人类在登录时做了哪些事情呢,很简单:
1. 打开登录页面
2. 输入用户名密码,有时可能还有验证码,各种各样的验证码
3. 点击登录
4. 等待浏览器自动跳转
只要你稍微懂一点html语言,就应该能分析个八九不离十。
机器人怎么做呢:
两种方式:
方式一:
需要使用虚拟的浏览器引擎。
优点: 适合几乎所有的网站登录,可以人为输入验证码
缺点: 速度较慢
1. 请求登录页面的url,比如微博的(https://passport.weibo.cn/signin/login)
2. 分析html中的表单数据
2.1 找到输入用户名、密码的输入框
2.2 把输入框的text域替换成自己的用户名密码
3. 模拟点击提交按钮
方式二:
分析登录信息提交方式,一般就是表单
优点: 轻量,速度快
缺点: 局限性大,对技术要求高,对验证码机制需要做针对的破解
1. 使用浏览器的调试模式查看网页
2. 检查是否使用表单提交
3. 点击登录按钮,查看发送的请求数据。主要查看参数有无加密验证或其它隐藏信息。
4. 使用分析结果进行请求操作
对于一般用户,所有的非特殊性需求都可以使用方式一进行完成。
若非是为了学习,推荐方式一。
技术资料请参考:
Python爬虫学习系列教程(推荐)
[Python爬虫] Selenium爬取新浪微博移动端热点话题及评论 (下)
如何让脚本的行为看起来像人?
为什么要像人
因为很多服务器会使用一些反爬技术拒绝爬虫软件访问。
哪些东西让你看起来像人,哪些不像人
像人,其实可以分为两点。
一类是看请求数据,是否符合是浏览器发出的正常数据,比如header内容。
一类是看行为模式,发送请求对象的行为更像人类还是机器人,比如请求的频率。
不像人,和上面对应。
从请求数据上看,你没说明user-agent,我就可以认为你是非法侵入。你没有带着我之前给你的饼干(cookie)来,我也可以拒绝你。
从行为模式上,同一个ip访问的频率过高,短时间内流量异常,都可以作为非人类处理。
结合反爬技术
- 需要登录用cookie
- ip限制加代理
- 用user-agent告诉对方你是浏览器
- 服务器限制访问频率,加延迟
- ajax异步加载,使用js引擎或者人工分析
- redirect,最简单的方式虚拟内核+延迟
- 验证码,虚拟内核
如何找切入点?
什么是好的登录页面?
没有验证码,非ajax异步加载。
不一定局限于pc端网页,app端、移动端一般做的反爬策略比较少,可以从这里入手,寻找适合的站点。
理解自己要做什么,如何伪装成人类。仔细思考访问流程,针对性的有哪些反爬手段。把这些想通了,爬虫之路会好走很多。
转载请注明:未命名的博客
相关文章和资料
技术语言资料请自行google。
使用Github的Webhooks进行网站的自动化部署
使用mWeb做自己的博客,服务器没有直接使用github的gh-pages功能,而是部署到了自己的服务器上。
从此更新博客变成了三步走:1. 使用mWeb生成静态网页 2. push 到github 3. 登录服务器拉取最新内容。
昨天想到,能不能再简化一些步骤,让我的文章push到github后,让服务器自动拉取文章,部署新内容。说干就干,实施想法。
1. 目标
服务器自动拉取push到github上的新文章。
2. 想法
想法一: 定时检查置顶repo的提交,有更新,则启动部署流程。(主动查询方式)
想法二: github是否支持事件提醒或者第三方有无支持。(被动唤醒方式)(相当于消息推送)
3. 思考
主动查询,耗费cpu时间及流量,并且必然会和github产生同步间隔。
被动唤醒,不会消耗不必要的资源,若是支持必然是第一选项。
4. 查阅资料(可行性分析)
github支持Webhooks及大量的第三方服务,可以很好得对repo的push等操作做出反应。
Webhooks做了什么?
当github收到repo的操作行为时,会向指定的url发送一个带有描述操作内容的post请求。
5. 实现思路(总结)
对指定repo注册webhooks,指向我的服务器上的接口,服务器解析数据,若操作是push,则进行部署行为。
6. 实现
6.1 部署脚本:
deploy.sh
#!/bin/bash
LOG_FILE="/var/log/blog_deploy.log"
date >> "$LOG_FILE"
echo "Start deployment" >>"$LOG_FILE"
cd /Path/need/be/deployed/
echo "pulling source code..." >> "$LOG_FILE"
git checkout origin gh-pages
git pull origin gh-pages
echo "Finished." >>"$LOG_FILE"
echo >> $LOG_FILE
每当接收到带push的post请求时,执行上面的脚本。
6.2 处理post请求
注:以下nodejs内容摘自曾曦前辈博客-尘埃落定
然后我们就要写一个脚本在 http://dev.lovelucy.info/incoming 这里接受 POST 请求了。因为本人机器上跑的是 node,俺就找了个 nodejs 的中间件 github-webhook-handler 。如果你要部署的是 PHP 网站,那你应该找一个世界上最好的语言 PHP 的版本,或者自己写一个,只需要接收 $_POST 嘛,好简单的,不多废话啦。么么哒 ( • ̀ω•́ )
$ npm install -g github-webhook-handler
鉴于在天朝的服务器上 npm 拉 repo 比拉屎还难的状况,我们可以 选用 阿里的镜像,据说 10 分钟和官方同步一次。_(:3 」∠ )_
$ npm install -g cnpm --registry=http://r.cnpmjs.org
$ cnpm install -g github-webhook-handler
好了,万事俱备,下面是 NodeJS 的监听程序 deploy.js
var http = require('http')
var createHandler = require('github-webhook-handler')
var handler = createHandler({ path: '/incoming', secret: 'myHashSecret' })
// 上面的 secret 保持和 GitHub 后台设置的一致
function run_cmd(cmd, args, callback) {
var spawn = require('child_process').spawn;
var child = spawn(cmd, args);
var resp = "";
child.stdout.on('data', function(buffer) { resp += buffer.toString(); });
child.stdout.on('end', function() { callback (resp) });
}
http.createServer(function (req, res) {
handler(req, res, function (err) {
res.statusCode = 404
res.end('no such location')
})
}).listen(7777)
handler.on('error', function (err) {
console.error('Error:', err.message)
})
handler.on('push', function (event) {
console.log('Received a push event for %s to %s',
event.payload.repository.name,
event.payload.ref);
run_cmd('sh', ['./deploy.sh'], function(text){ console.log(text) });
})
/*
handler.on('issues', function (event) {
console.log('Received an issue event for % action=%s: #%d %s',
event.payload.repository.name,
event.payload.action,
event.payload.issue.number,
event.payload.issue.title)
})
*/
之后把服务器跑起来就可以了。
$ nodejs deploy.js
为了防止服务挂掉,我们有很多方式可以处理。我选择了用系统自带的nohup。
$ nohup nodejs deply.js &
曾曦前辈使用的是 NodeJs的forever,也可以使用python的supervisor。
曾曦前辈博客-尘埃落定有相关介绍。
6.3 配置Webhooks监听
将Payload URL指向自己服务器的接口
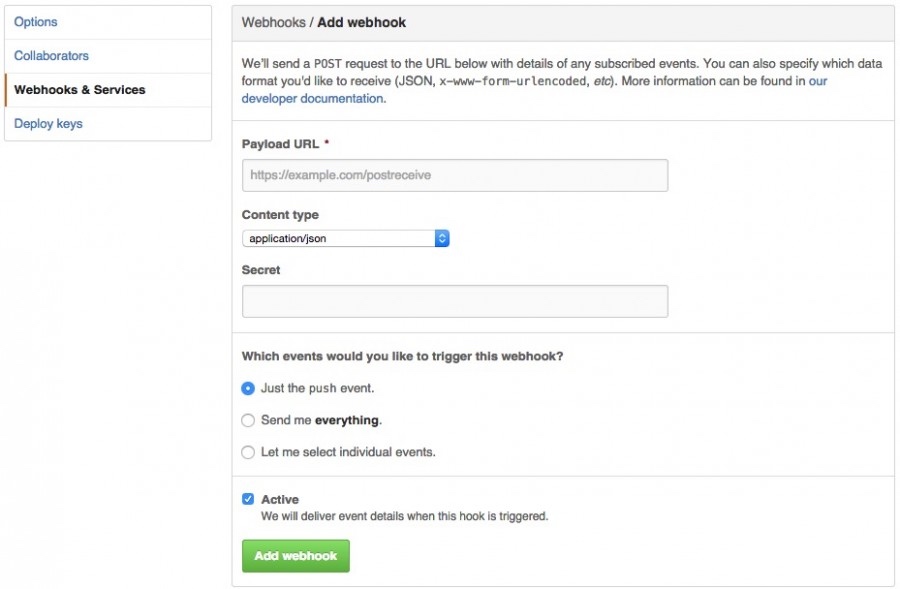
var handler = createHandler({ path: '/incoming', secret: 'myHashSecret' })
http.createServer(function (req, res) {
handler(req, res, function (err) {
res.statusCode = 404
res.end('no such location')
})
}).listen(7777)
这是deploy.js 的关键代码。
listen(7777),表明服务器监听的是7777端口
path:'/incoming',表示在 ip:7777/incoming 接收POST请求
secret: 'myHashSecret', 要求和上图的Secret字段一样,不然服务器会因为不匹配,拒绝接收到的请求。主要为了防止第三方向这个端口发送请求。
7. 最后梳理一下
6.3 那里知道什么时候有人提交文章了,然后告诉6.2 有人push
6.2 从6.3 得到消息,看下你的密码(secret)和我的一样不,如果一样,我就把这个消息告诉6.1
6.1 开始跑到github数据库拉取最新的数据,部署完成
澄清
有朋友告诉我,复制粘贴的部分比较多。即便加了转载说明,也不是很好。
在这里澄清一下:
网络上技术文章特点:多,杂,全
可用的经典实例: 少
自生产实例的成本: 费时
一篇全原创的优质文章需要:思考+原创实例+码字+重复前三项 。
而对于学习者而言,思想+实例+思路已经满足80%。
所以我认为,一篇能学到东西的技术文章,并不需要全原创。
清晰的思路+前人提供的经典实例+个人思考,传达到位即可。
前人都总结好了,你再发一遍,不是制造网络垃圾吗?
打造一个以思路清晰著称的博客,专注于技术文章整理、重成文是本博客存在的意义。我不是垃圾的生产者,我是大自然的清道夫。
欢迎关注个人微博斯科特安的时间 ,进行技术、非技术交流。
10分钟快速搭建无限制流量的"VPN"(shadowsocks协议)
Too Long No Read: 阅读标题和标重点部分就能了解全部内容。
1. 简介
良心声明: 有朋友说10分钟根本连文章都看不完,哪能建起个自己完全不熟悉的V P N 呢?
所以在这里必须解释一波:10分钟指的是开始动手到可以使用的时间。并不包括读这篇文章的时间,也不包括你在搭建服务过程中自我纠结的时间(比如,租多大的服务器?用什么密码?剁完手后又要饿多久的肚子才能给女票买下件内衣?之类。别问我为什么知道你一定是男的)最后,不包括运行出错,调试测试的时间。因为,按我说的做,你根本不可能失败!
接下来是简介:
说是无限制流量,其实骗你的啦(可爱)。说是VPN,其实不限于VPN。(本文搭建的也不是VPN,而是被称为Shadowsocks的协议。)
接下来解释:
原理: 租一个国外的服务器 -->这个服务器上搭建自己的VPN --> 通过这个VPN科学上网。
无限制流量:500G,1T,甚至更多。一月这么多,用的完吗?用不完不就相当于无限制。
VPN:既然有了自己墙外的服务器,就可以用它搭建任何自己想要的科学上网利器。本文章主要介绍当下最安全、最流行的ShadowSocks.
价格:很便宜!!很便宜!!很便宜!!
2. 工具篇
2.1 VPS 国外的服务器
VPS:Virtual Private Server 虚拟专用服务器
其实你就知道是个自己能用来搭建科学上网服务的主机就行了。
一般不了解的人,第一反应都是:卧槽,我指用个10G流量只能翻墙的VPN就几十块一个月。那租一个可以干很多事情、不限流量的服务器,岂不要几百几千?其实不用998、不用98,绝对用你想不到的价格,买到最不可思议的产品!
2019新年限时特惠!Vultr 虚拟服务器注册即得50美元奖励金!
点击注册得50美金
仅此一个月!
推荐:
1. 搬瓦工 (稳定推荐)
优点:便宜!!最低500G流量,年购19.99美刀,使用优惠码还可以再减1刀左右。相当于每月10元。这价格已经比大多数VPN便宜了。
支持支付宝交易!
支持30天内退款 一般一个工作日内就能回复,支付宝收到2~3天。
一键配置shadowsocks!如果使用搬瓦工,那后面的内容都不用看了,点下面的链接注册即可。
官方网址:https://bandwagonhost.com/
如果被墙也可使用: https://bwh8.net
两个都是官方地址
数据中心:美国西雅图、佛罗里达、洛杉矶、荷兰 套餐价格:64MB内存年3.99美元 / 96MB内存年4.99美元/128MB内存年5.99美元/512MB内存年9.99美元 简单介绍:IT7官方旗下的低价VPS主机产品,拥有速度较好的西岸亚利桑那州机房,最低年付仅需3.99美元,我们可以用来学习、工作项目演示,以及需要支持PPP/TUN搭建工具使用需求。拥有4个数据中心,而且可以自由切换IP,更换不同的IP,解决IP被封问题。
最新资料 可登录搬瓦工中文资料站进行查看
搬瓦工中文
2. Vultr (低价推荐,我自己目前在用)
2019新年限时特惠!注册即得50美元奖励金!
点击注册得50美金
仅此一个月!
注册网址
优点
1. 注册赠送20美金。使用最低标准服务5刀/月,相当于可以免费使用4个月。(活动已经失效,但最低标准服务价格下调到2.5刀/月,可以说是相当实惠了!)
2. 服务稳定。至少我还没碰到过当机情况。
3. 第三点是缺点,想获得20美金,必须使用信用卡支付,并且扣除2.5美元的验证费。(以后会返还)
4. 现在已全面支持支付宝/微信付款,非常方便,也不需要绑定信用卡了。
点击注册并获取20美金
数据中心:日本、洛杉矶、英国、法国、德国、荷兰、澳大利亚等14个机房
套餐价格:KVM 768MB 15GB SSD 1TB月流量 $5/月
简单介绍:Vultr作为全球最大的游戏主机提供商背景之一,上线之后以高质的性价比、12个数据中心,以及新注册账户赠送5美金的账户使用金优惠促销,吸引广大的用户。作为我们用户,日本、洛杉矶等数据中心速度较好,如果有需要海外其他机房也可以在其12个数据中心中选择到适合自己的。
3. 其它
因为我指用过上面两个,所以其他的也不多介绍了。列个列表,大家可以自行google。
Linode: 很多人推荐。速度快。价格中等。
DigitalOcean: 很多人推荐。速度快,价格差不多。
为什么说价格便宜
除了明码标价的价格。其实本身已经和普通VPN价格差不多了。但是仍然,有一点。虽然流量并不是无限,但是带宽并没有限制。就是说,在流量还够用的前提下,和朋友一起使用,是几乎不影响访问速度的,价格又能再除以...,最后折算下来非常可观。当然,不能超越物理极限,3、5个人一起用,是保险又便利的方式。
价格上,贵就是好
对于同类物品,贵就是好。所以无论是我提到的,还是没提到的,虽然价格有差异,但是毕竟体现在服务好坏上。所以,如果你发现不同价格,买到了同样的配置,但是实际效果却有差距,这很正常。
2.2 Python Shadowsocks 搭建服务的工具和协议
Shadowsocks 属于socks5 代理,稳定性好,抗干扰能力强。
搭建服务 三步走
1 . 安装
在CentOS中运行下面两条命令就完成了shadowsocks的安装了:
yum install python-setuptools && easy_install pip
pip install shadowsocks
2 . 配置
完成之后创建一个配置文件 /etc/shadowsocks.json,写入以下内容:
{
"server":"0.0.0.0", #服务器IP地址
"server_port":8388, #服务监听端口
"local_port":1080, #本地连接端口
"password":"barfoo", #加密传输使用到的密码
"timeout":600, #连接超时时间
"method":"aes-256-cfb" #加密算法
}
3 . 启动、停止
运行下面的命令来启动和停止后台服务:
ssserver -c /etc/shadowsocks.json -d start
ssserver -c /etc/shadowsocks.json -d stop
然后你就可以使用上面的配置连接shadowsocks了。
- 客户端如何用?
各个平台使用的客户端都有差异,但是用到的信息就这些:
- 服务器IP: 不是上面的0.0.0.0,是你申请的VPS,会提供一个ip。打开网站,登录,找到它
- 端口(port): 8388
- 协议类型: aes-256-cfb 一般默认就这个,不用换。但还是要看一眼。
- 密码(password): barfoo
连接,欢呼。
Copyright © 2015 Powered by MWeb, Theme used GitHub CSS.